Many people think building AI agents is mostly about the LLM. In reality, most of the complexity sits in the infrastructure around it.
In my previous article(https://aiforproduction.blog/2026/03/12/what-openclaws-architecture-taught-me-about-building-real-genai-systemspart-1/), I explored the architectural challenges behind building systems like OpenClaw — things like always-on infrastructure, memory management, tool execution, and concurrency.
Today, I want to share what I found interesting about how OpenClaw actually addresses these problems.
When studying systems like this, it’s useful to compare:
Problem → Naive solution → Real architecture
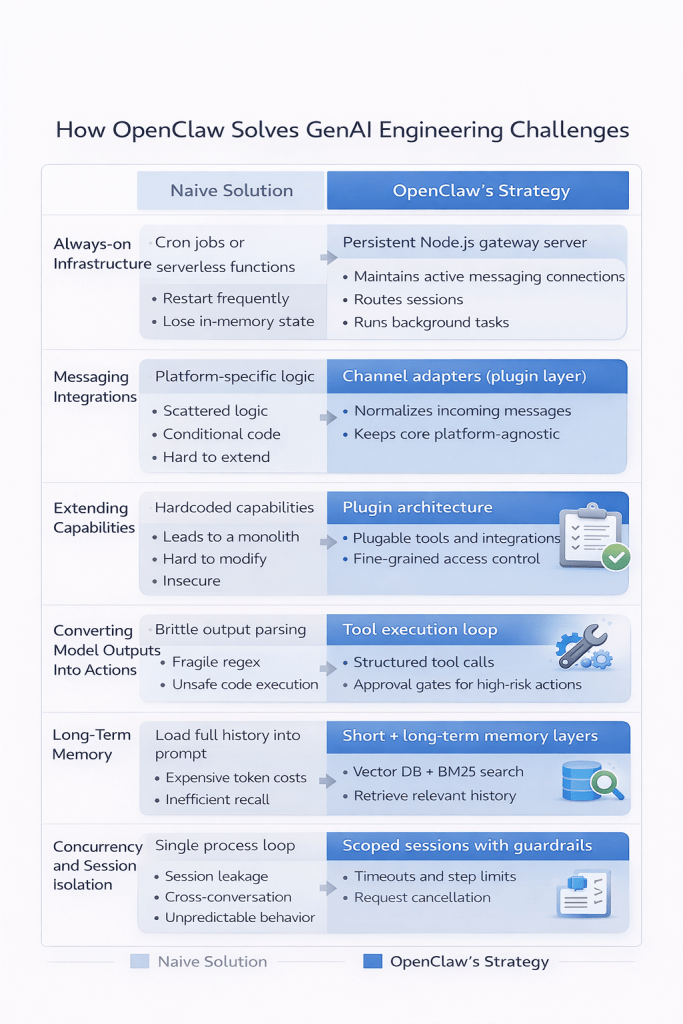
Let’s look at each in detail.
Challenge 1: The system must never sleep
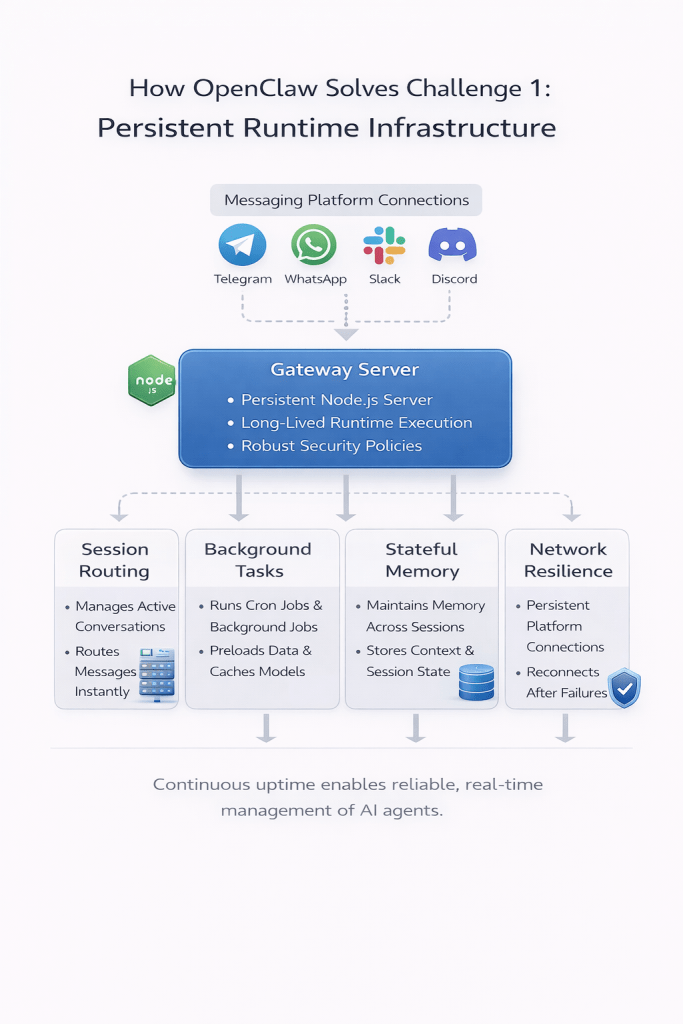
The problem
- An AI assistant must be available 24/7, maintain session state, and respond instantly to messages.
Naive solution
- Use cron jobs or serverless functions.
These work initially but fail because they:
- restart frequently
- loose in-memory state
- cannot maintain persistent connections
How OpenClaw solves it
- OpenClaw runs as a persistent Node.js gateway server that stays alive continuously.
- This gateway maintains connections to messaging platforms, routes sessions, and runs background tasks — enabling the system to behave like a long-running AI assistant.
Challenge 2. Messaging platforms introduce hidden complexity
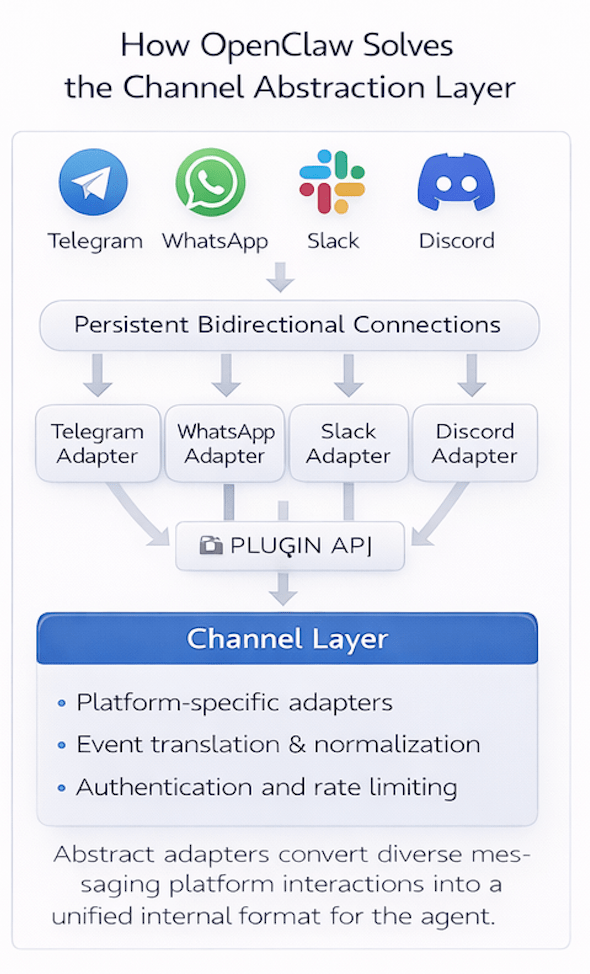
The problem
Supporting multiple messaging platforms quickly introduces complexity.
Each platform has different:
- authentication models
- event systems
- message formats
- rate limits
Naive solution
Write platform-specific logic directly into the core application. Over time, this spreads conditional logic across the codebase.
How OpenClaw solves it
- OpenClaw introduces a Channel Layer.
- Each platform is implemented as a plugin adapter that converts messages into a normalized internal format.
- This keeps the core system platform-agnostic.
Challenge 3. Capabilities must evolve without breaking the core
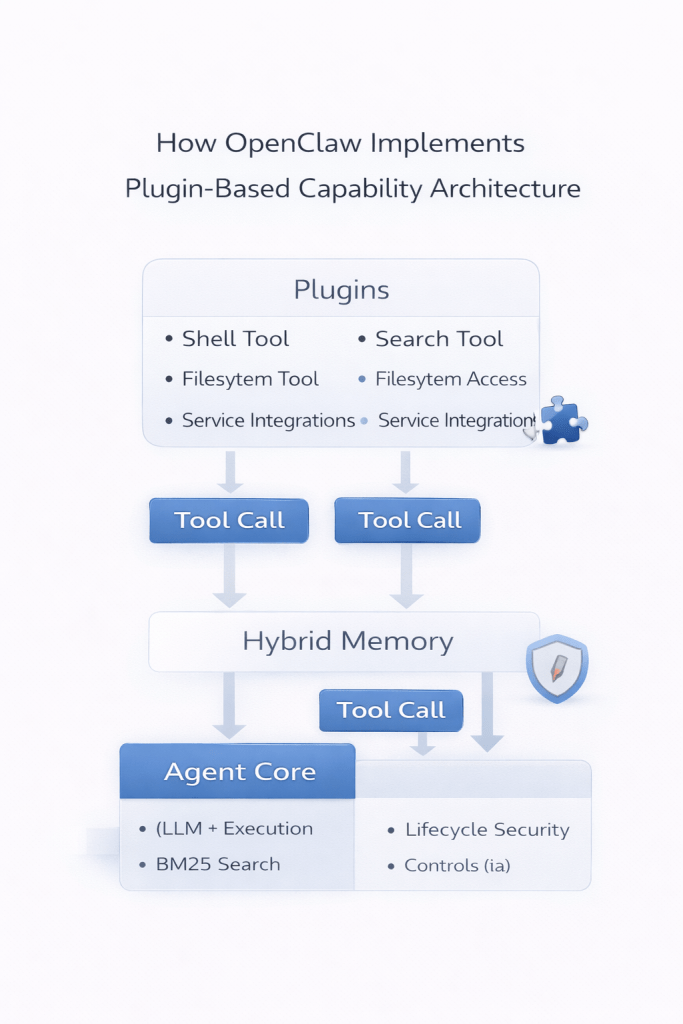
The problem
Agents need tools like filesystem access, shell execution, web search, and API integrations.
Naive solution
- Add tools directly into the core runtime.
This quickly leads to a monolithic architecture that is difficult to extend or secure.
How OpenClaw solves it
OpenClaw uses a plugin architecture.
Plugins can:
- register tools
- integrate external services
- run background tasks
- hook into lifecycle events
This allows capabilities to evolve without modifying the core runtime.
Challenge 4. Turning model output into real actions
The problem
LLMs generate text, but agents must execute real-world actions.
Naive solution
- Prompt the model to output structured commands and parse them directly.
This approach is brittle and hard to control safely.
How OpenClaw solves it
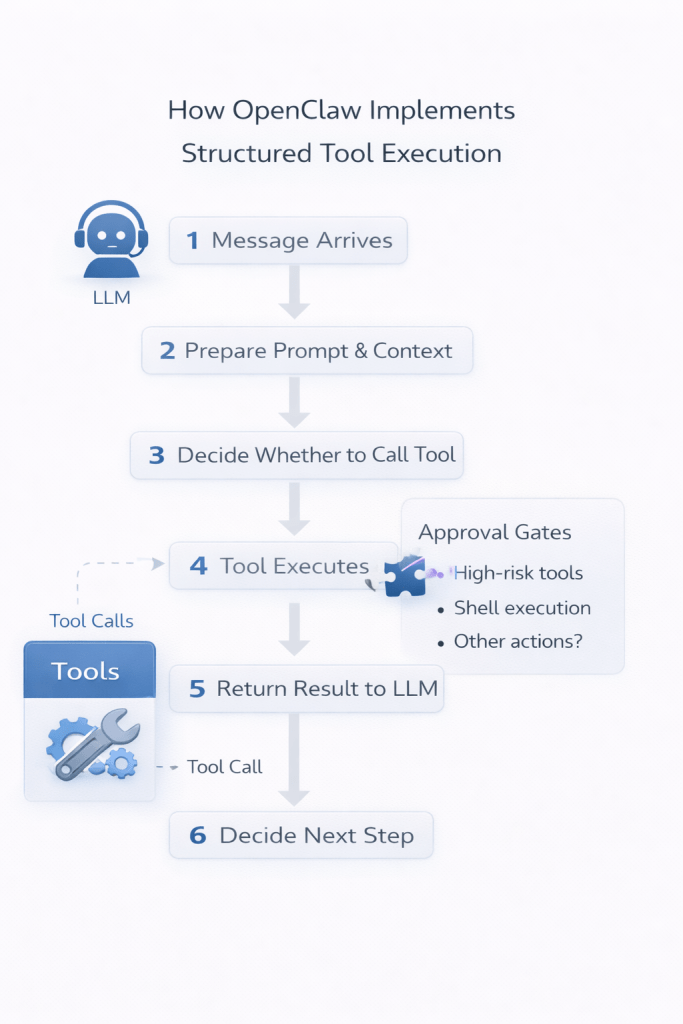
OpenClaw uses a structured tool execution loop:
- A message arrives
- The system prepares context and prompt
- The LLM decides whether to call a tool
- The tool executes
- The result is returned to the model
This loop continues until a final response is produced.
Importantly, approval gates can intercept high-risk tool calls before execution.
Challenge 5. Memory across sessions
The problem
Keeping entire conversation histories in the prompt quickly becomes expensive and exceeds context limits.
Naive solution
- Load all previous messages into the context window.
This increases the cost and eventually breaks.
How OpenClaw solves it
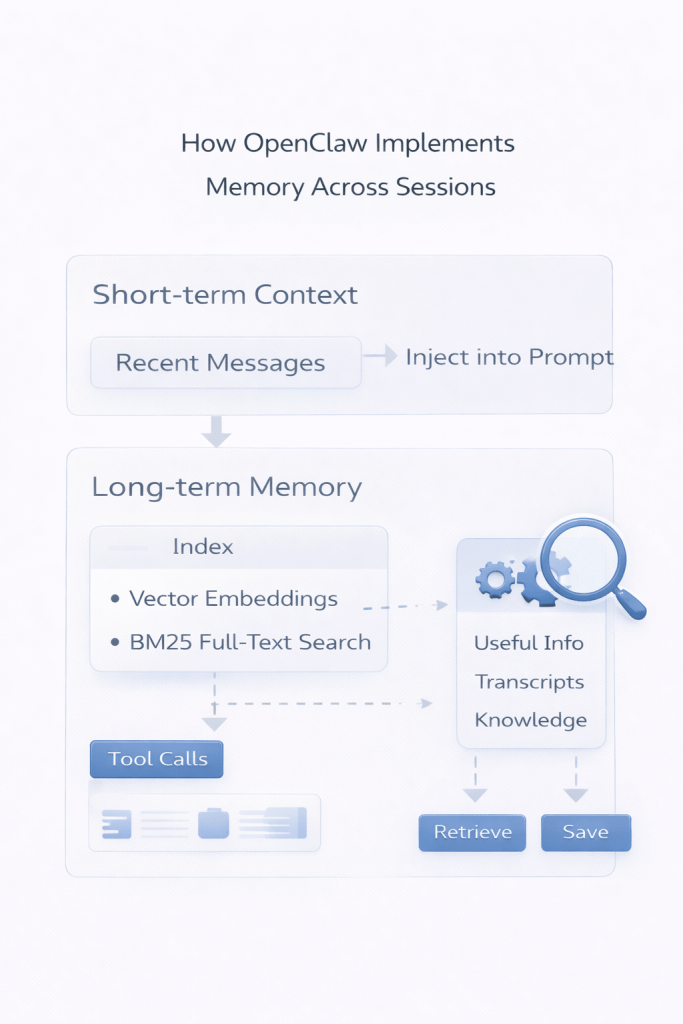
OpenClaw separates memory into two layers:
- Short-term context – recent conversation history
- Long-term memory – transcripts indexed using:
- vector embeddings
- BM25 full-text search
Relevant information can then be retrieved and injected into the prompt when needed.
Challenge 6. Concurrency and session isolation
The problem
Real systems must handle multiple users, background tasks, and long-running tool calls simultaneously.
Naive solution
- Run everything in a single process loop.
This often leads to session leakage and unpredictable behavior.
How OpenClaw solves it
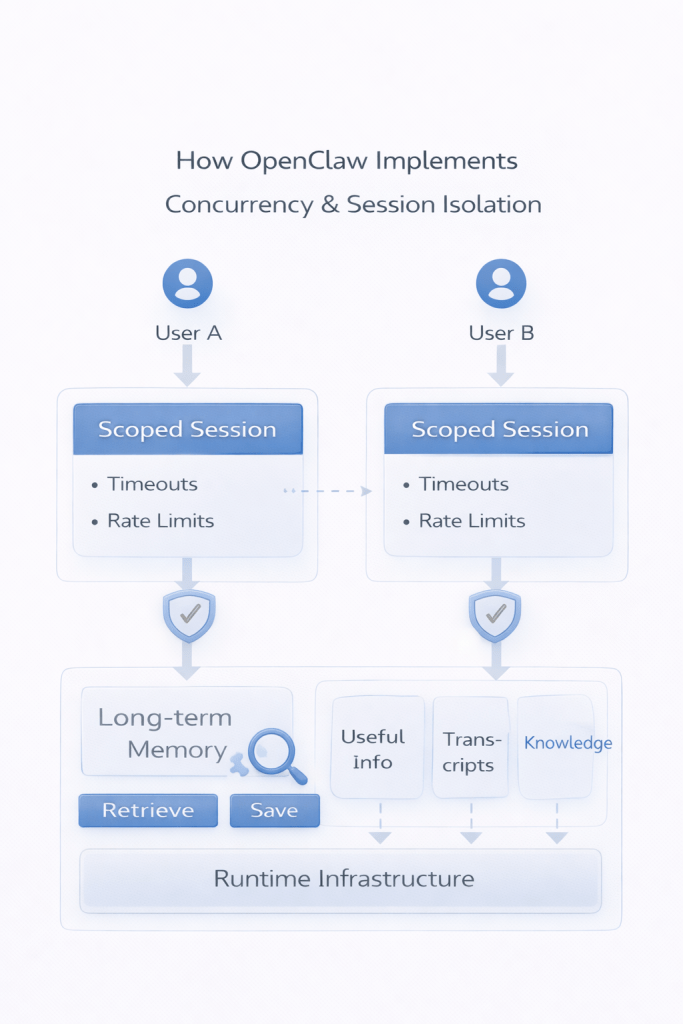
OpenClaw introduces clear session scoping, routing rules, and guardrails, including:
- step limits
- request timeouts
- cancellation mechanisms
These help ensure the system remains stable under real workloads.
Final takeaway
Exploring OpenClaw reinforced something important:
Building scalable GenAI systems is fundamentally a systems engineering problem.
The LLM is just one component. The real architecture lives in runtime infrastructure, memory systems, tool orchestration, and safety layers.
Why this matters beyond OpenClaw
These architectural patterns are not unique to OpenClaw. You’ll see similar ideas in LangGraph, AutoGPT, Devin-style agents, and enterprise AI systems.
The core challenge is no longer just building models — it’s building reliable systems around them.
The real architecture lies in designing:
- reliable runtime infrastructure
- safe tool orchestration
- scalable memory systems
- extensible architectures
- robust session management
In 2026 a lot more products we see are trying to solve the ecosystem problem. And perhaps that is what we need to think of in the longer term too.
