Over the past few days, I’ve been exploring OpenClaw and trying to run parts of it locally.
As someone working on production GenAI systems, I’m always curious about how different frameworks approach building AI agents that operate in real environments.
What stood out while studying OpenClaw is something I keep seeing across many GenAI systems:
The hard problems are rarely the LLM itself.
They are everything around the LLM.
At first glance, building something like OpenClaw looks straightforward.
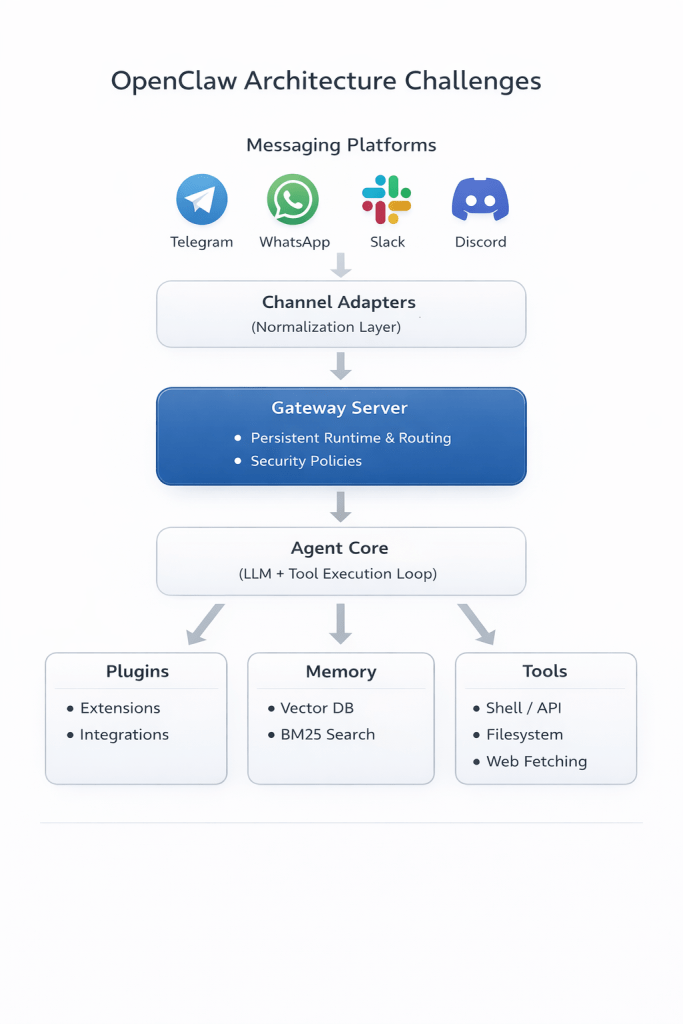
You could:
- spin up a Node.js server
- connect it to Telegram or Slack
- call an LLM API
- parse tool calls
And technically, that might work for a demo.
But the real engineering begins after the first working version.
Once you try to build something that runs reliably in real-world environments, several architectural challenges quickly appear.
Challenge 1: The system must never sleep
An AI assistant is expected to be available 24/7.
It must:
- receive messages instantly
- maintain session state across conversations
- run background tasks
- trigger actions when needed
The naive approach
A common first attempt is to run the agent using simple scheduling or stateless infrastructure.
For example:
- Cron jobs that periodically check for new messages
- Each run starts from a blank state
- Conversations cannot easily resume mid-flow
- Responses are limited to scheduled intervals rather than real-time events
- Serverless functions that process incoming requests
- Each invocation starts fresh and terminates after completion
- Maintaining persistent connections or in-memory state becomes difficult
Both approaches reveal an important requirement:
- Agent systems need a long-lived runtime that stays active between interactions.
Challenge 2. Messaging platforms introduce hidden complexity
Supporting one messaging platform is manageable. Supporting several quickly becomes complex.
Platforms such as Telegram, Slack, Discord, and WhatsApp each have different:
- authentication flows
- event delivery mechanisms
- connection protocols
- message formats
- rate limits
The naive approach
Most systems begin with support for a single platform.
For example:
- Implement a Telegram bot integration
- Later, add Slack or Discord support
Over time:
- Platform-specific logic spreads across the codebase
- Developers introduce conditional routing logic, such as:
if platform == "telegram":
handleTelegram()if platform == "slack":
handleSlack()
This gradually introduces challenges such as:
- platform-specific edge cases
- multiple authentication flows
- inconsistent message formats
- different connection protocols
Without clear abstraction layers, platform-specific logic spreads across the codebase, making the system difficult to maintain.
Challenge 3. Capabilities must evolve without breaking the core
A useful assistant needs tools. Examples include:
- filesystem access
- shell execution
- web search
- API integrations
If these capabilities are tightly coupled to the core runtime, the system quickly becomes monolithic.
The naive approach
Initially, new capabilities are added directly to the core application.
Typical examples include:
- filesystem access
- shell execution
- web search
- external API integrations
Over time, this leads to:
- growing dependencies inside the core runtime
- tightly coupled configuration and implementation
- difficulty enabling or disabling features
Scalable systems require architectures that allow capabilities to evolve independently of the core system.
Challenge 4. Turning model output into real actions
LLMs generate text. Agents must execute actions.
Bridging this gap requires infrastructure that can:
- interpret model intent
- Execute tools safely
- manage multi-step workflows
- enforce security policies
The naive approach
One common strategy is to ask the language model to produce structured outputs describing actions.
For example:
{
"tool": "shell",
"command": "ls -la"
}
The application then:
- parses the structured output
- executes the requested action
However, this approach introduces several issues:
- Models sometimes produce malformed structures
- parsing logic becomes fragile
- Multi-step workflows require complex control loops
Even more importantly:
- It becomes difficult to introduce clear safety checks before execution.
Challenge 5. Memory across sessions
Keeping the entire conversation history within the model’s context window may seem like a simple solution.
The naive approach
A straightforward approach to memory is to include the entire conversation history inside the prompt.
This works for short interactions, but quickly creates problems:
- Context windows are limited
- token costs increase rapidly
- long conversations become inefficient to process
This highlights an architectural need to separate:
- short-term conversational context
- long-term knowledge retrieval
Real-world systems need mechanisms that balance short-term conversational context with long-term memory retrieval.
Challenge 6. Concurrency and session isolation
Finally, real systems must handle multiple conversations and tasks simultaneously.
This includes:
- parallel conversations
- long-running tool executions
- background processes
The naive approach
Early implementations often process requests sequentially. This works for simple prototypes but fails when real usage patterns appear.
Typical situations include:
- Multiple users sending messages simultaneously
- long-running tool calls are still executing
- background tasks running in parallel
Without proper isolation mechanisms, this can lead to:
- session leakage between conversations
- blocking operations that freeze the system
- unpredictable interactions between concurrent tasks
Final thoughts
Now that we have seen the naive approaches, the next article is going to explore how OpenCLAW solved them.
Studying systems like OpenClaw is a good reminder that building scalable GenAI systems is fundamentally a systems engineering problem.
The interesting work is not just prompting models. It is designing the infrastructure that allows AI systems to operate reliably, safely, and continuously.
As GenAI systems evolve, scalable architectures will likely focus less on the model itself and more on the surrounding infrastructure:
- runtime environments
- memory layers
- tool orchestration
- integrations
- safety mechanisms
Links:
- https://docs.openclaw.ai/concepts/architecture
- https://www.youtube.com/watch?v=CAbrRTu5xcw
- https://ppaolo.substack.com/p/openclaw-system-architecture-overview
What’s next
In a follow-up article, I’ll explore how OpenClaw’s architecture addresses these challenges and what design patterns we can learn from it.
