This series started because of a 1–1 conversation with a reportee. One of my reportees asked me a simple question:
“With everything happening in AI… should I be worried, and what will happen to jobs in 5-10 years?”
It wasn’t a dramatic question. It wasn’t about headlines. It was about career, growth, and uncertainty.
That conversation stayed with me. And as i researched , this is not a single person, but has been coming out in multiple surveys too:
Highlights:
- 60% of workers believe AI will eliminate more jobs than it creates in the year ahead.
- 12% expect AI to create more jobs than it eliminates.
- 51% of workers say they are worried about losing their jobs to AI or automation in 2026.
I’ve been reading a lot of perspectives online last couple of months about AI and jobs. Most of them make strong points, but many focus on just one slice of the problem — technology, economics, productivity, or fear — without really looking at it holistically.
Through my work on the GenAI platform at a Fortune 50 company, I’ve had the opportunity to speak with a wide range of stakeholders: Business leaders, Product teams, Legal, Finance, Developers, Data Scientists, and Operations. Each group sees AI through a different lens. That exposure made me realize that the conversation around jobs and AI needs to be broader and more grounded.
To do that properly, I felt we needed to start at the most concrete layer — the code itself — and then expand outward to organizational structures, and finally to the societal implications.
So I’m breaking this into a three-part series:
- Part 1 – The Fear:
Let’s address what everyone is worried about, using a real example and an actual experiment.
- Part 2 – The Big Picture:
Once we see what AI can do at a task level, how does that translate into a business context and organizational impact?
- Part 3 – Where Are We Headed?
If we understand both the technical and business layers, what does that mean for us as individuals?
This first article focuses purely on a hands-on comparison: Human (AI-assisted) vs Agent-driven approaches to building a model to solve a business problem.
Problem Statement:
Build a model to predict user consumption patterns for a bike-sharing company for the EU market
From a business perspective, they want a solution that’s fast to market, not hard to maintain and follows GDPR guidelines.
We try two things here:-
1.) Build a Jupiter notebook by hand, go through the process of EDA, feature engineering, modelling, hyperparameter training, and arrive at a solution. Use AI here to help with the generation of helper functions, using code stubs from actual libraries.
2.) Use antigravity with the Claude 4.6 Opus model for coding tasks to build a langraph-based agent that does the same thing. I gave the agent the following problem statement and data to build a model on, and asked for a Jupyter notebook as an output
Post this I need to run some standarized tests for GDSP compliance.
What is my goal here:
Try running an actual experiment to demonstrate where AI does well vs humans. This would give an indication of areas of disruption.
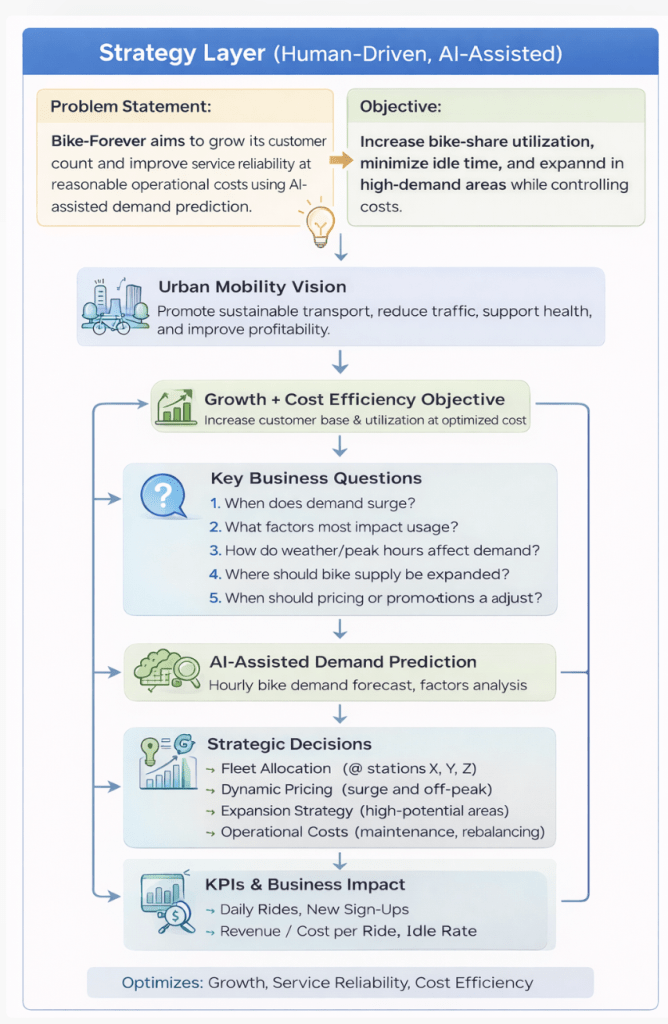
Problem Statement (Human-driven, AI-assisted)
Bike-sharing systems modernize traditional rentals by automating membership, booking, and returns. Users can pick up a bike at one location and drop it off at another. With over 500 programs and 500,000+ bikes worldwide, these systems play a key role in improving urban mobility, sustainability, and public health.
Objective (Human-driven, AI-assisted)
Bike-Forever, a bike-sharing company, aims to grow its customer base and improve service efficiency while controlling costs. The company has collected two years of data covering weather, weekends, holidays, and other factors.
As a data scientist at Bike-Forever, your task is to:
- Analyze usage patterns and identify key factors influencing bike demand
- Determine what drives the target variable (bike rental count)
- Build a predictive model to forecast demand, especially during surge hours
- Provide actionable business recommendations based on the analysis
What Do We Infer about the Problem:(Human-driven, AI-assisted)
- Answer times and factors leading to surge of bikes.
- Decision of effects of weather and other paramters.
- Identify pricing per locality
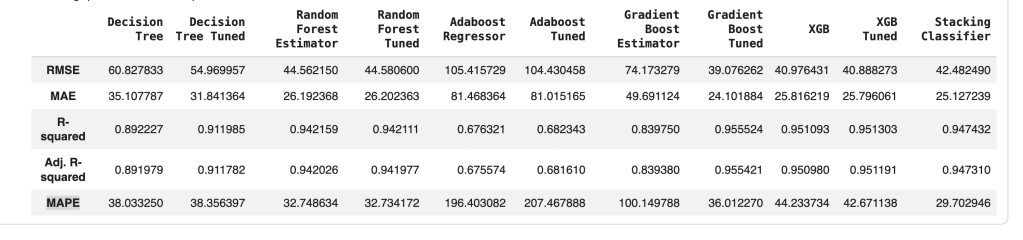
- It is a regression problem, and so we might need to focus on evaluating for RMSE, MAE, R-squared, and Adj. R-squared and MAPE.
- Let’s say we want to optimize for R-squared
- AI can assist in analysis or building code for analysis and understanding patterns better but human oversight is needed.
What AI inferred:
The Design:(Human vs Agent)
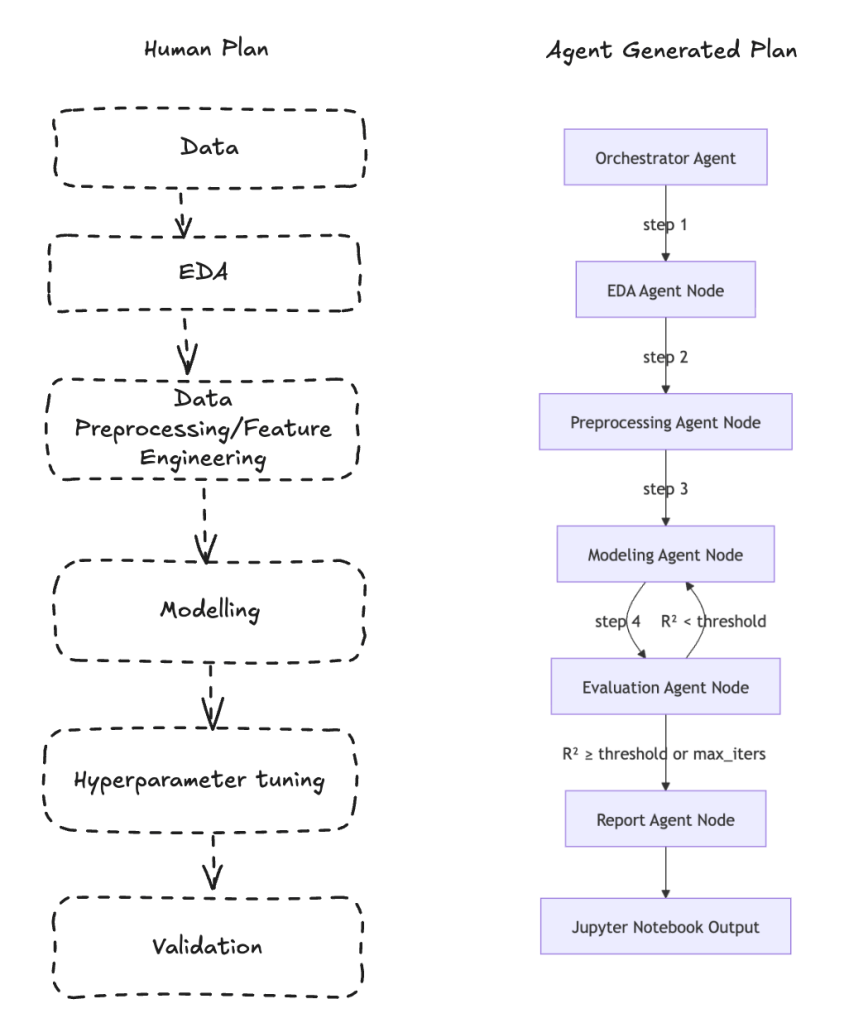
What Actually Happened:
HUMAN DRIVEN:
It took me approximately 2 days to use the pseudocode from what I had with AI assistance to create features, fix errors, and get a working notebook. This is a summary of my test results.
Notebook: https://colab.research.google.com/drive/1u_M9lN8Un15bn0lC6JINnEiBsbddDK4-?usp=sharing
AGENT DRIVEN:
I fed the data, I asked the model to focus on R2 and added the problem statement and instructions in my document. Let antigravity run in agent mode and left to run as is. IL attach the jupyter notebook built for reference too.
Notebook:
https://drive.google.com/file/d/1m6G-nCWLG9TkliVSVAnKXIp9Ct91YvQE/view?usp=sharing
GDPR Compliance:
https://drive.google.com/file/d/1sMRwO32ZDN0SHUEb_hNATWchoVVrqZQO/view?usp=sharing
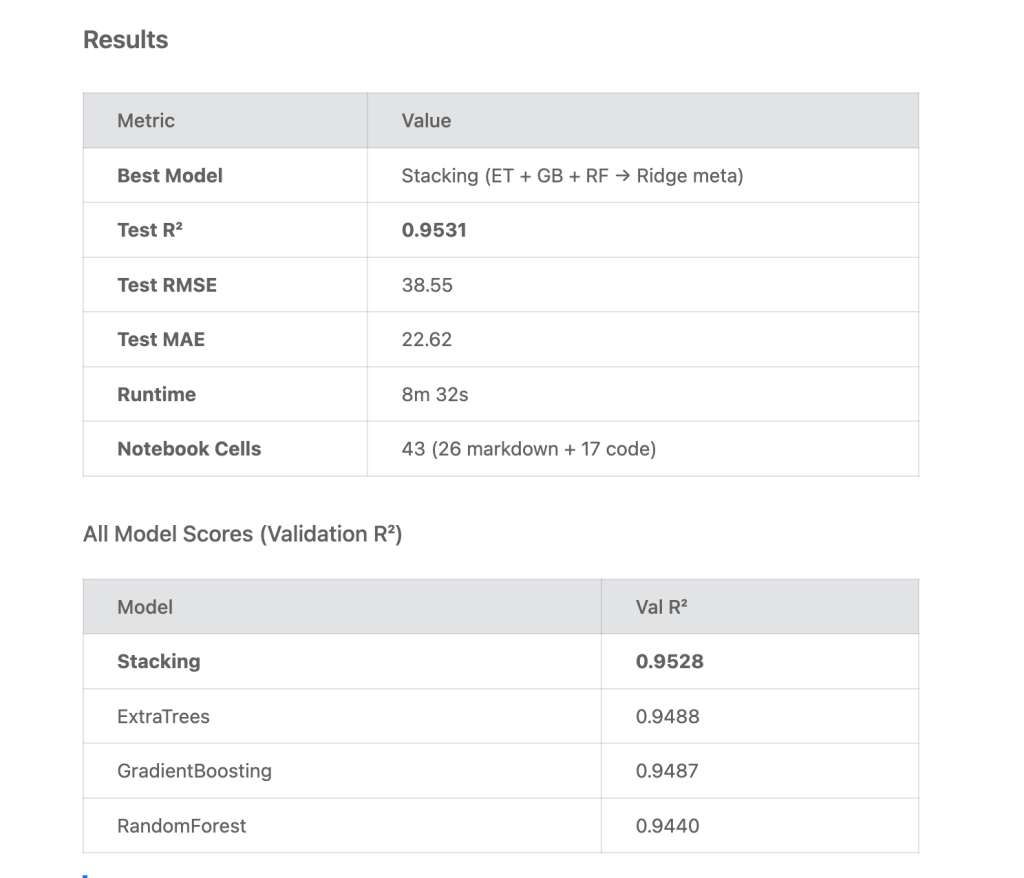
The agent produced results that are very close to — and in some cases slightly better than — my manual approach..
GDSPR score card:

An AI agent has not only been able to independently create a model that is equivalent if not better than a human but also create a GDPR compliance report.
If you’ve never worked on real-world deployments, this might look like the end of the road for developers. This creates fear and panic.
As professionals, we don’t just look at the R² score and call it a day.
We start asking questions:
- Did we really understand the data?
- Did we check for leakage?
- Did we think about deployment constraints?
- What happens when the data changes?
- Who owns monitoring?
- Does this model fit the business strategy?
The agent optimized for R² because I told it to. But in real life, business problems are rarely just about one metric.
The real question isn’t: “Can AI build a model?” It clearly can.
The bigger question is: “What part of the lifecycle is actually being automated — and what part still needs judgment?”
- Yes, AI shortens EDA.
- Yes, it speeds up modeling.
- Yes, it can generate documentation.
But building a model is not the same as building a production system that drives business value. And that’s where the fear starts to look different.
Maybe this isn’t about jobs disappearing. Maybe it’s about roles shifting and merging.
In the next article, I want to zoom out. If AI can compress task execution, what happens to:
- Team structures?
- Product timelines?
- Cost models?
- Decision-making layers?
That’s the bigger picture. Understanding current organizational structures and looking at how things could change. Because disruption doesn’t happen at the notebook level.
It happens at the organization level. Let’s go there next.
