When it comes to today’s AI systems, especially in Generative AI, the main challenge isn’t just building a basic system with, say, 70% accuracy—it’s about pushing that system to over 90% and making it reliable for real-world production.
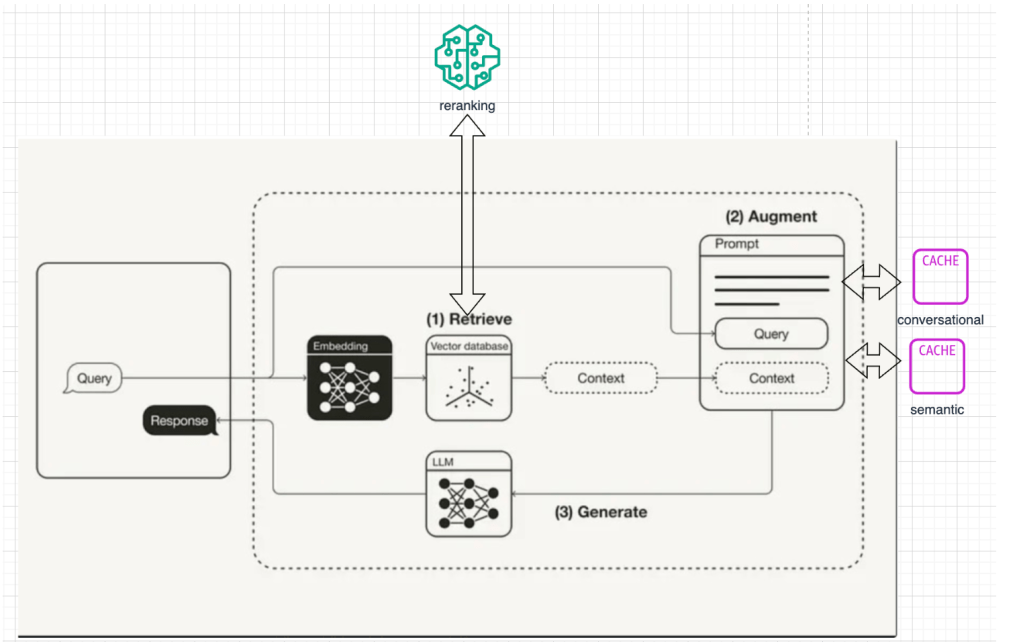
Optimizing RAG (Retrieval-Augmented Generation) systems is essential for reaching this level. Effective chunking, one of the foundational steps in optimizing RAG, allows these systems to interpret and retrieve information more accurately, making it a key focus area for robust performance. Lets take a brief look at a basic rag architecture before we go to specific methods.
BASIC RAG ARCHITECTURE:
RAG or Retreival Augmented Generation is a method that enhances generative AI by retrieving relevant information from external sources to improve accuracy and context in responses.
Chunking 30,000 SUMMARY:
Below are the chunking streatiges we will be looking at today.
- Character Chunking: Splits text into fixed-size, context-agnostic chunks, ideal for fast processing of structured content like legal databases or messages.
- Recursive Chunking: Breaks down text hierarchically, first by larger units (e.g., paragraphs) and then by smaller ones, useful for retaining structure in complex documents.
- Sentence Chunking: Divides text by sentences, preserving semantic integrity for contexts like FAQs or knowledge bases.
- Page-wise Chunking: Segments text by fixed page-like divisions, ideal for digitized documents where each page has logical or thematic breaks.
- Semantic Chunking: Groups text based on topic coherence using embeddings, effective for nuanced texts like scientific papers or dense articles.
- Agent-based Chunking: Chunks text by markers (e.g., section headers or speaker turns), making it useful for dialogue-based or thematically distinct documents.
Paragraph to Chunk:
We will take the below paragraph as example to try out our chunking
You don't have to be French to enjoy a decent red wine," Charles Jousselin de Gruse used to tell his foreign guests whenever he entertained them in Paris. "But you do have to be French to recognize one," he would add with a laugh.
After a lifetime in the French diplomatic corps, the Count de Gruse lived with his wife in an elegant townhouse on Quai Voltaire. He was a likeable man, cultivated of course, with a well-deserved reputation as a generous host and an amusing raconteur.
This evening's guests were all European and all equally convinced that immigration was at the root of Europe's problems. Charles de Gruse said nothing. He had always concealed his contempt for such ideas. And, in any case, he had never much cared for these particular guests.
The first of the red Bordeaux was being served with the veal, and one of the guests turned to de Gruse.
"Come on, Charles, it's simple arithmetic. Nothing to do with race or colour. You must've had bags of experience of this sort of thing. What d'you say?"
"Yes, General. Bags!
USER QUESTIONS:
- What is the summary of the user paragraph?
- Which content is the event happening in?
- Where is the make of the wine that is being served?
How to think of Chunking and RAG:
Think of yourself as a librarian, and AI as a super-smart kid asking about a specific topic. Your job is to hand over just the right amount of information for it to understand and answer a user question—not too much, so it doesn’t get overwhelmed, and not too little, so it can still answer accurately.

Now, let’s say you have only 3-4 chunks to use as context for your LLM. If the chunks are too large, it’ll take longer to process. If they’re too small, the LLM might start hallucinating. This is where having the right chunking strategy really matters.
Chunking Strategies Deep Dive:
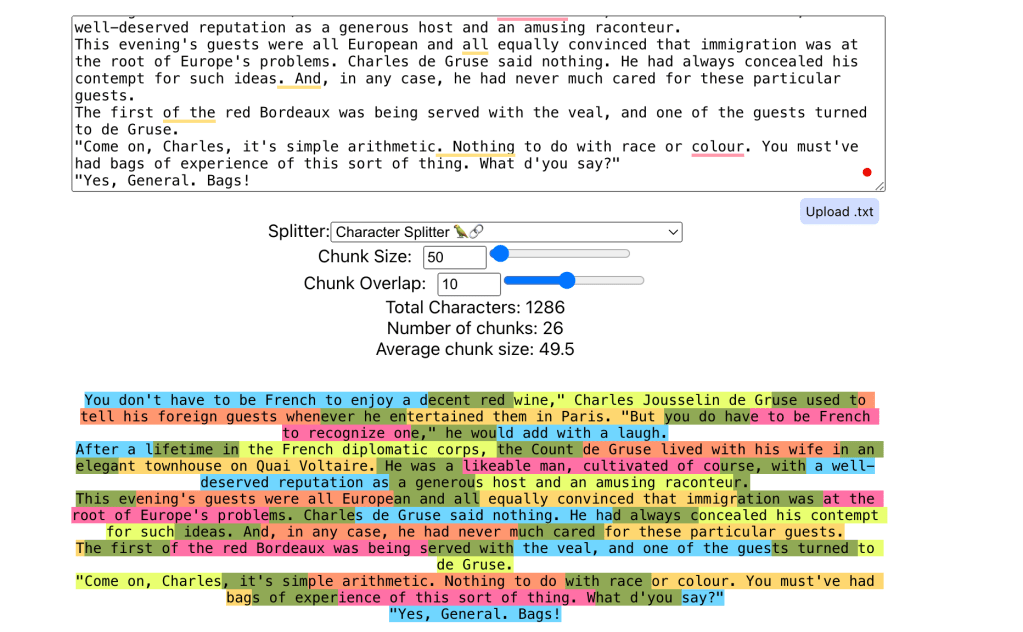
1. Character Chunking:
- Description: Simple static character chunks of data. It is often used for fixed-size segments without consideration for context.
- Use Case: Fast Processing of Structured Content with Fixed Limits
- Example: Character chunking is ideal when you need quick access to specific sections within structured text, like legal case databases, where each chunk is treated as an isolated fact, or when segmenting chat messages or tweets with strict length limitations.
- Advantages: Fast to implement, offers consistent chunk sizes without context consideration, and maintains readability in cases where the text doesn’t require nuanced division.
Code:
# Level 1 - Character Splitting
print("Level 1: Character Splitting")
# Initialize CharacterTextSplitter with chunk size and overlap
text_splitter = CharacterTextSplitter(chunk_size = 100, chunk_overlap=10, separator='', strip_whitespace=False)
# Split text into chunks
character_chunks = text_splitter.split_text(sample_text)
# Print results
print("\nCharacter Splitting Results:")
for i, chunk in enumerate(character_chunks):
print(f"Chunk {i + 1}: {chunk}")Visualization: Each color represents a chunk that is created by the character splitter
2. Recursive Chunking:
- Description: Initially chunks by larger units (e.g., paragraphs). If a chunk exceeds the specified limit, it’s recursively broken down into smaller chunks.
- Use Case: Hierarchical Texts with Variable Contextual Depth
- Example: Documents with nested structures, such as policy papers or technical manuals, benefit from recursive chunking. For instance, a policy document could initially be chunked by sections; if sections are too large, they can then be broken down into paragraphs, sentences, and words as needed.
- Advantages: Retains hierarchical structure, making it effective for documents that may need to preserve context down to a very fine-grained level when large chunks violate the system’s length limit.
Code:
# Level 2 - Recursive Character Text Splitting
print("\nLevel 2: Recursive Character Text Splitting")
recursive_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=10,
separators=["\n\n", "\n", " ", ""]
)
recursive_chunks = recursive_splitter.split_text(sample_text)
print("\nRecursive Character Splitting Results:")
for i, chunk in enumerate(recursive_chunks):
print(f"Chunk {i + 1}: {chunk}")Visualization:

3. Sentence Chunking:
- Description: Chunks text by sentences, ensuring no chunk exceeds the defined size. It keeps the semantic integrity of sentences when using this method.
- Use Case: Context-Preserving Semantic Retrieval
- Example: Sentence chunking is valuable for FAQ-style systems or customer support knowledge bases. If each question and answer is chunked as a sentence, it allows for retrieval based on specific questions without requiring overly complex processing.
- Advantages: Ideal for short and contextually complete information pieces, preserving the integrity of responses, FAQs, or quotes without splitting at unnatural points, ensuring coherent retrieval.
Code:
# Level 3 - Sentence chunking Splitting
import nltk
from nltk.tokenize import sent_tokenize
# Ensure you have downloaded the punkt tokenizer
nltk.download('punkt')
# Function for sentence chunking
def sentence_chunking(text):
sentences = sent_tokenize(text)
return sentences
# Apply sentence chunking
sentence_chunks = sentence_chunking(sample_text)
# Display results
print("Sentence Chunking Results:")
for i, chunk in enumerate(sentence_chunks):
print(f"{i+1}: {chunk}")Visualization:

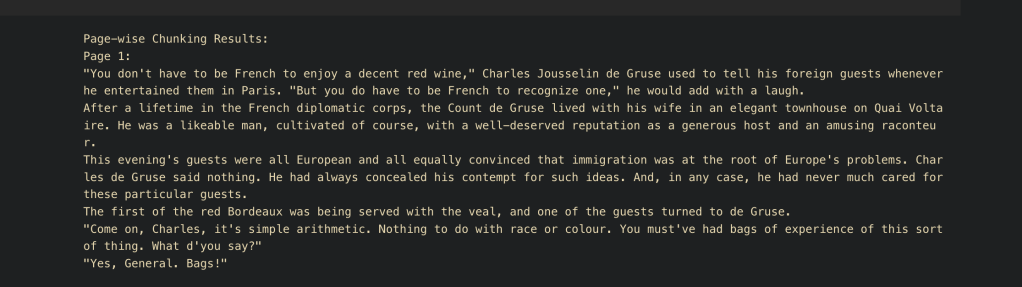
4. Page-wise Chunking:
- Description: Chunks the text based on a fixed size, mimicking how pages might be chunked. Let’s say on an average we see each page contains 200 words, we split our document by page chunks.
- Use Case: Digitized Documents with Fixed Logical Divisions
- Example: When working with e-books, reports, or scanned PDFs where each page forms a natural break, page-wise chunking can be helpful. For instance, analyzing academic books where each page covers a topic or has a certain flow that should be preserved for context.
- Advantages: Efficient for printed documents, making it easier to correlate specific pages in retrieval, which aligns with content in the physical document. Works well for analysis and maintaining references.
Code:
# Level 4 - Page-wise Chunking
from langchain.text_splitter import CharacterTextSplitter
# Create a TextSplitter configured for page-wise chunking
# Here we set a fixed size for each "page" chunk
page_size = 200 # Each page chunk will be 200 characters
page_splitter = CharacterTextSplitter(
chunk_size=page_size, # Fixed page size
chunk_overlap=0 # No overlap between chunks
)
# Perform the page-wise chunking
page_chunks = page_splitter.split_text(sample_text)
# Output the page-wise chunks
print("Page-wise Chunking Results:")
for i, chunk in enumerate(page_chunks, 1):
print(f"Page {i}:\n{chunk}\n")Visualization:
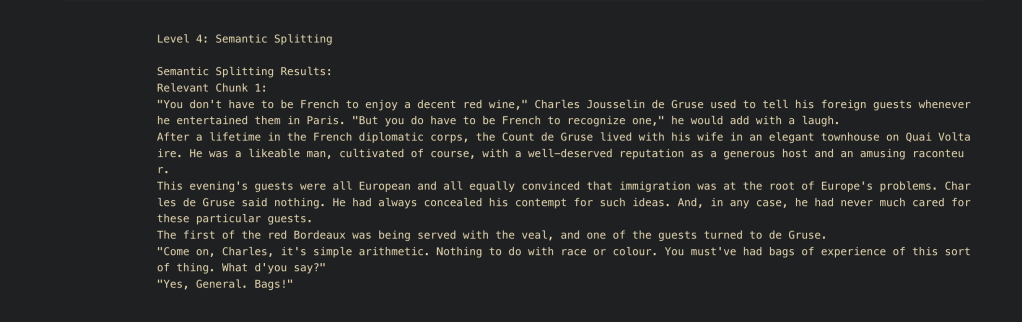
5. Semantic Chunking:
- Description: Leverages a pre-trained model (e.g., Sentence Transformers) to chunk text based on semantic similarity.
- Clarification: Highlight that this method is beneficial for detecting nuanced meanings in the text, making it suitable for complex datasets.
- Use Case: Complex Texts with Dense, Thematic Information
- Example: For datasets like scientific papers, news articles, or technical documentation, semantic chunking is useful for segmenting by topics rather than fixed sizes. For instance, a medical paper could be chunked by topic (symptoms, diagnosis, treatment) rather than by arbitrary length.
- Advantages: Creates meaningful, cohesive chunks based on topic coherence, improving retrieval for systems that rely on nuanced understanding, like recommendation engines or domain-specific search applications.
Code:
# Level 5 - Semantic Splitting with Embeddings
print("\nLevel 4: Semantic Splitting")
# Initialize embeddings and vector store
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_texts([sample_text], embedding=embeddings)
# Retrieve chunks based on semantic similarity
query = "tell me about french wine?"
docs = vector_store.similarity_search(query, k=3)
print("\nSemantic Splitting Results:")
for i, doc in enumerate(docs):
print(f"Relevant Chunk {i + 1}: {doc.page_content}")Visualization:
6. Agent-based Chunking:
- Description: Simulates chunking based on markers such as section headers or dialog.
- Use Case: Dialogue-Based or Thematically Distinct Texts
- Example: For transcribed conversations, interview notes, or storytelling with clear dialogue breaks, agent-based chunking ensures each speaker’s contributions are grouped cohesively. In a corporate report that alternates between financial summaries and departmental updates, it helps in chunking distinct thematic sections.
- Advantages: Retains logical sections based on structural markers like speaker turns or document headers, enhancing clarity in retrieval applications that need distinct roles or thematic segments, such as in chatbot training or narrative-based systems.
Code:
# Level 6 - Agentic Splitting (Experimental)
print("\nLevel 5: Agentic Splitting (Experimental)")
def agentic_splitter(text, keywords=["chunking", "splitting", "technique"]):
# Example: Split based on the presence of keywords
chunks = []
temp_chunk = ""
for word in text.split():
temp_chunk += word + " "
if any(keyword in word.lower() for keyword in keywords):
chunks.append(temp_chunk.strip())
temp_chunk = ""
if temp_chunk:
chunks.append(temp_chunk.strip())
return chunks
agentic_chunks = agentic_splitter(sample_text)
print("\nAgentic Splitting Results:")
for i, chunk in enumerate(agentic_chunks):
print(f"Agentic Chunk {i + 1}: {chunk}")Visualization:
Ending Thoughts:
Chunking is one of the way of optimizing rag, there are many many more ways to optimize RAG. We will be taking a look at other strategies to optimize rag in further posts.
RAG 10,000 Feet:
https://aiforproduction.wordpress.com/2024/03/16/rag-components-10000-ft-level/
