A lot of the buzz is around GEN AI from the last couple of years. The focus on GPU has increased significantly. Building a good understanding of why we need each and when is essentially to build our foundational understanding.
So let’s dive in. We will start by looking at the theory of both, then run some benchmarks on GPU vs CPU. And we close this with a high-level summary of GPU VS CPU
Note: We will benchmark with the below compute
- CPU: Intel(R) Xeon(R) CPU @ 2.20GHz
- GPU: NVIDIA Tesla T4
GPU VS CPU FOR LAYMAN:
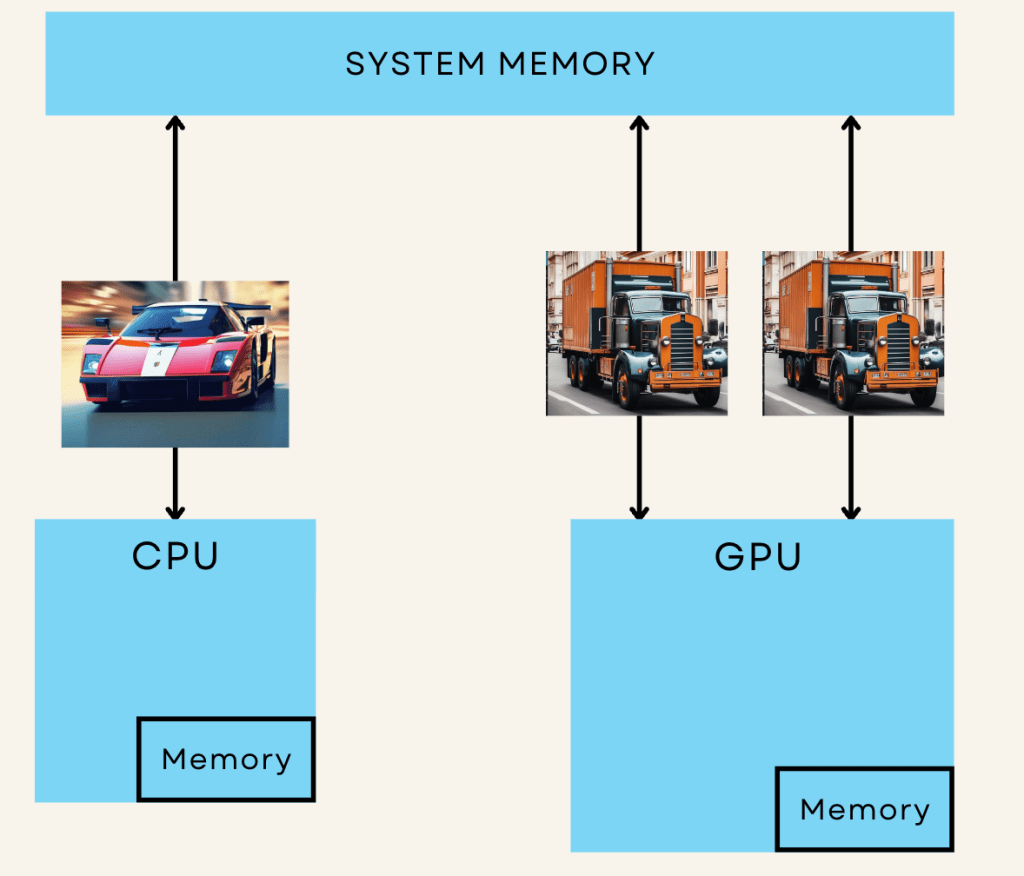
A CPU is like a car optimized to run and finish a single task in the fastest way possible. A GPU is like a truck designed to carry heavy specialized work loads.

- CPU handles general-purpose tasks designed to execute instructions one after the other, from running operating systems to managing applications.
- GPU is primarily designed for handling graphics and image processing. GPU excels at performing multiple calculations at the same time.
Now that we know GPU is good for handling parallel processing why do we need this in deep learning?
NEED FOR PARALLEL PROCESSING IN DEEP LEARNING:
Matrix multiplication is the cornerstone of neural networks. It powers both training and inference by efficiently processing data through layers, enabling the model to learn and make predictions.
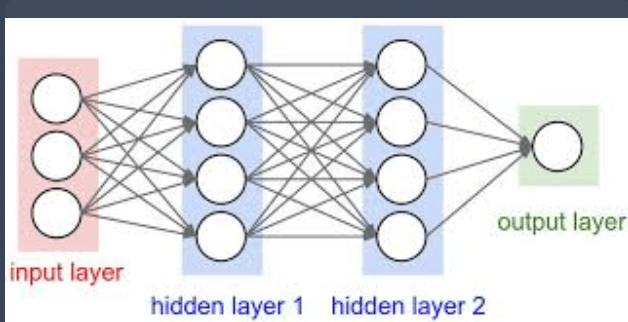
If the above seems easy lets try visualizing the number of matrix multiplications below. It is huge and there in comes the need to specialized hardware.

Okay so wev established that neural networks needs matrix multiplication. We still need to understand why we need GPU. We also need to know why CPU cant be used.
Benchmarking CPU VS GPU: Simple vs Complex Operations
Scalar Multiplication:(Simple operations)
Scalar multiplication involves doing one operation at a time. Lets consider a scalar k=2 and 2*2 matrix = [[1, 2], [3, 4]]
To do scalar multiplication, you multiply each element of the matrix A by scalar k.
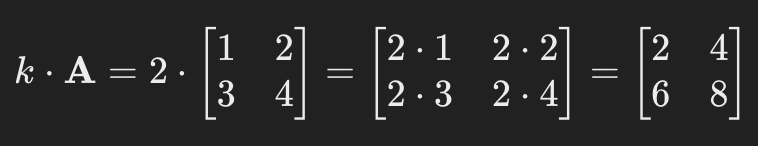
How does this look in a CPU vs GPU, lets try visualizing:

Lets do a quick test on google collab to see how this performs.
CPU Test:(Google collab CPU ) – 13.2 microseconds

GPU Test:(NVIDIA T4) – 11.2 microseconds

The performance looks similar on the onset but the differences are considerable as the number of operations increases. Let’s take a look.
Also one point to consider is the cost different between the hardware.
Matrix Multiplication:
Matrix multiplication involves multiple parallel operations being done parallely. Lets see how with an example:
A = [[1, 2], [3, 4]] , B = [[4, 5], [6, 7]]
A * B = [[(1*4) + (2*6), (1*5) + (2*7)],
[(3*4) + (4*6), (3*5) + (4*7)]]
= [[16, 19], [36, 43]]
All the above operations can be done in parallel. Now instead of a 2*2 matrix imagine we have a 10000*10000 matrix and now think of how parallelization adds value. This is where GPU really excels. Lets test this.
CPU Test:(Google collab CPU ) – 29.7 seconds

GPU Test:(NVIDIA T4) – 16.4 seconds

You can see that as the number of matrix operations are increasing GPU is clearly performing better.
This shows why we have had such a huge explosion in usage of GPU’s. Lets summarize everything we know until now
SUMMARY:
| Feature | CPU (Central Processing Unit) | GPU (Graphics Processing Unit) |
| Architecture | General-purpose processors designed for a wide range of tasks. | Specialized processors designed for parallel processing. |
| Cores | Fewer, more powerful cores optimized for single-threaded performance. | Thousands of smaller, efficient cores optimized for parallel tasks. |
| Functionality | Suited for tasks requiring complex logic and decision-making, like running operating systems and complex calculations. | Suited for tasks that can be parallelized, like graphics rendering, deep learning, and scientific simulations. |
| Low-Level Work | Executes instructions, handles arithmetic, logic, control, and I/O operations. | It processes large data blocks simultaneously. It performs parallel computations. This is ideal for rendering images, videos, and training machine learning models. |
| Average Cost | $100 – $500 (consumer grade) | $200 – $1000 (consumer grade) |
Final Thoughts:
We are in an age where there is an explosion of GEN AI and LLM’s. We have great models that perform really great during experiments but are not memory efficient to run in production.
This has to change over time and the start of all this is with understanding compute and GPU.
It is important to understand the need for GPU, understand its usage, and improve on cost to start with.
