Have you ever done text generation with an LLM and though: I wish I could track experiments and evaluate different LLM results in terms of cost, sample comparison and memory together like below?

If yes this article for you.
Experimentation tracking is one critical piece of model development which is very important as it helps compare different setting that we can run a model with. And this helps with tuning a model and understanding which model we want to use in production.
With traditional models runs , we can track hyper parameters and other metrics like accuracy, precision and also individual features.
With LLM’s , a lot of the existing use cases for I have seen is with using LLM’s directly with existing models(Eg. openai, azure or google’s gen AI api’s) with either zero shot learning, one shot or few short learning plugging in a RAG in the backend.
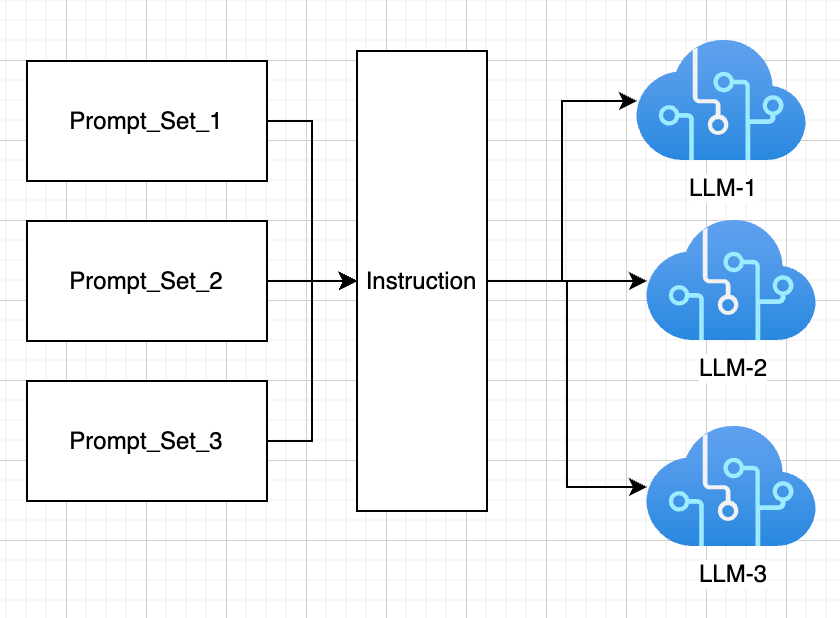
Evaluation of LLM’s currently is a mix of checking measures like bleu score and rouge score and more often than not an SME from businesses checking the results manually and also wanting to understand the cost. The flow looks something like below:-
We start from here(few llm and prompt combinations):
We end here(after trial and error we find the right LLM and prompt templates/system instructions to use):
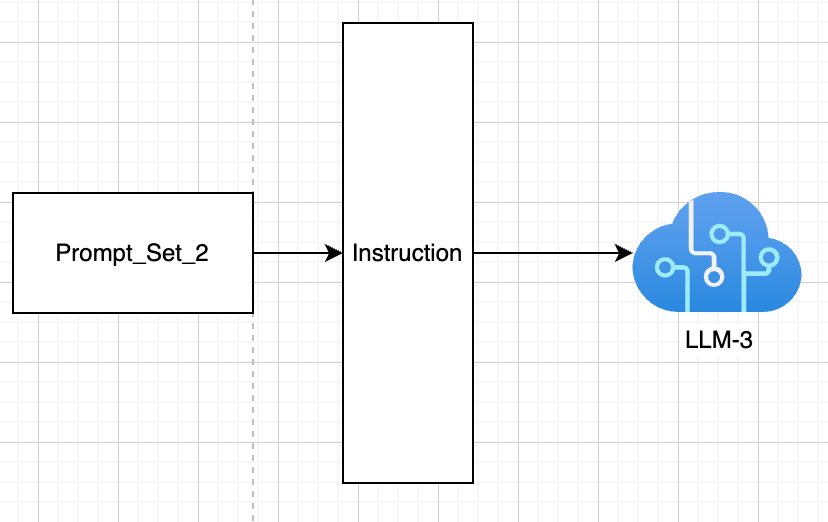
We came from 3 models and 3 prompts to 1 model and 1 prompt. We did this manually. But what if we had a lot more models and lot more prompts. That is where experiment tracking is important:-
With llm experiments the below information becomes helpful along with statistical measures(bleu score, rogue-1 score etc):-
- system prompt(instruction)
- user prompt
- model used
- number of tokens
- cost per request
- time to complete inference request
Along with this , it also helps to understand the memory and disk utilisation. As I was searching for this I happened to notice weights and biases can be used to achieve something like this.
Use Case:
I want to use LLM to generate a game character name based on the assets/persona given.
I want to generate names for the below assets:-
- Hero name inside the game
- Name for a precious in gem stone
I use the below system prompt.
System prompt : “You are a creative copywriter. You’re given a category of game asset, \
and your goal is to design a name of that asset.The game is set in a fantasy world where everyone laughs and respects each other, while celebrating diversity.”
I use 3 different models to experiment and see which generated the most appropriate output and also understand the number of tokens that I need:-
- gpt-3.5-turbo
- gpt-3.5-turbo-0125
- gpt-4
I run inference with the 3 models and get the below results:-

I can visually make sense of which might be good and which might be bad, but I also need to understand the inference time, the number of tokens against each other.
That is where weights and biases was helpful. We do the below:-
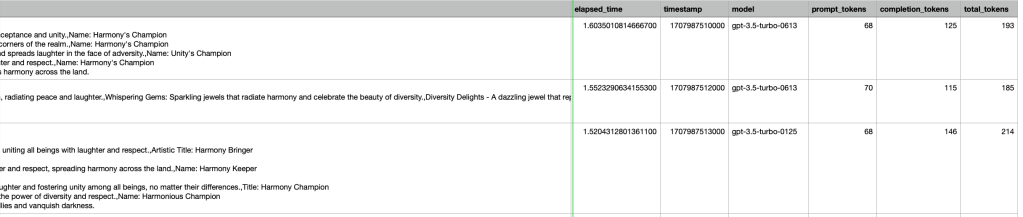
- We create a weights and biases table with the columns system_prompt, user_prompt, generations, elapsed_time, timestamp, model, prompt_tokens, completion_tokens, total_tokens.
- We already have all this information at the user end. We log this table.
EXPERIMENT TRACKING RESULTS:
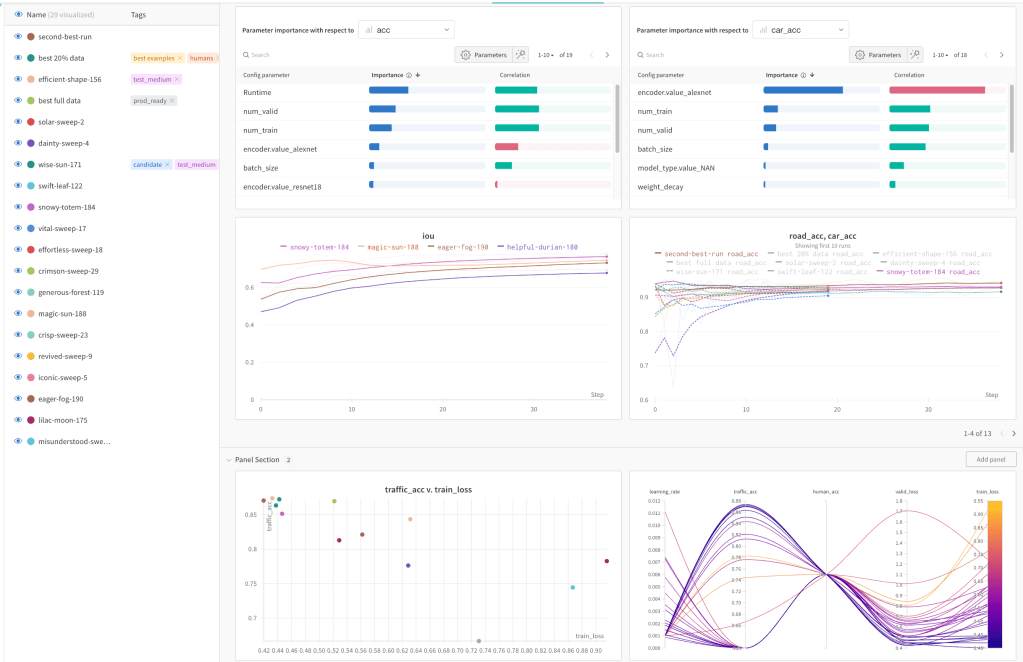
Using above I can get the below using weights and biases:-
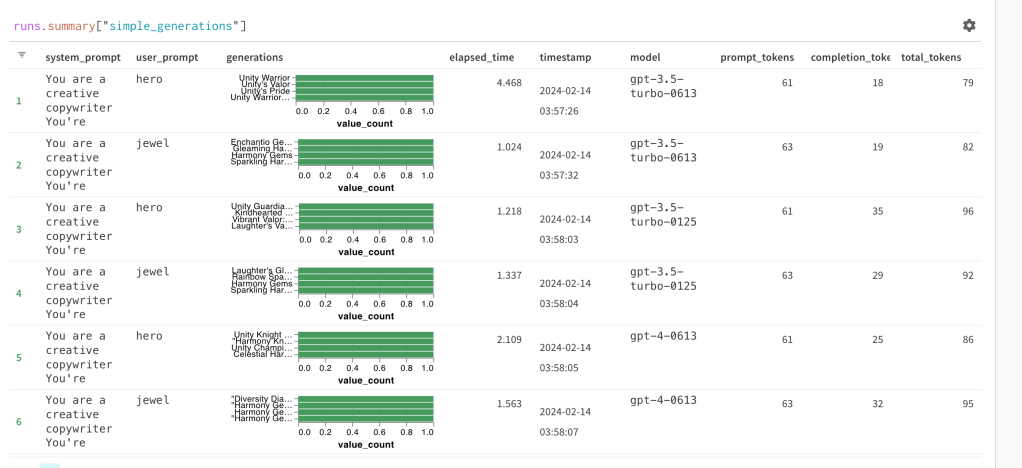
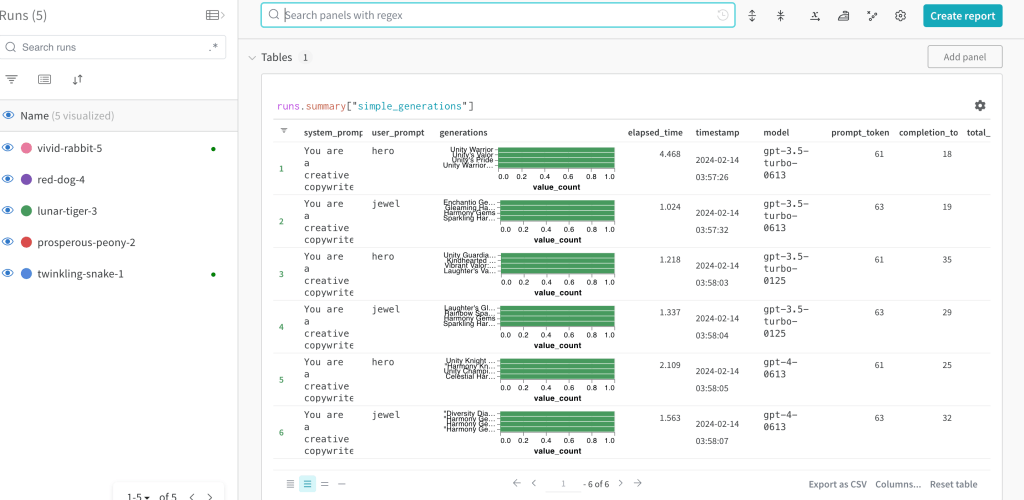
I can also compare different runs that I execute at different times:-
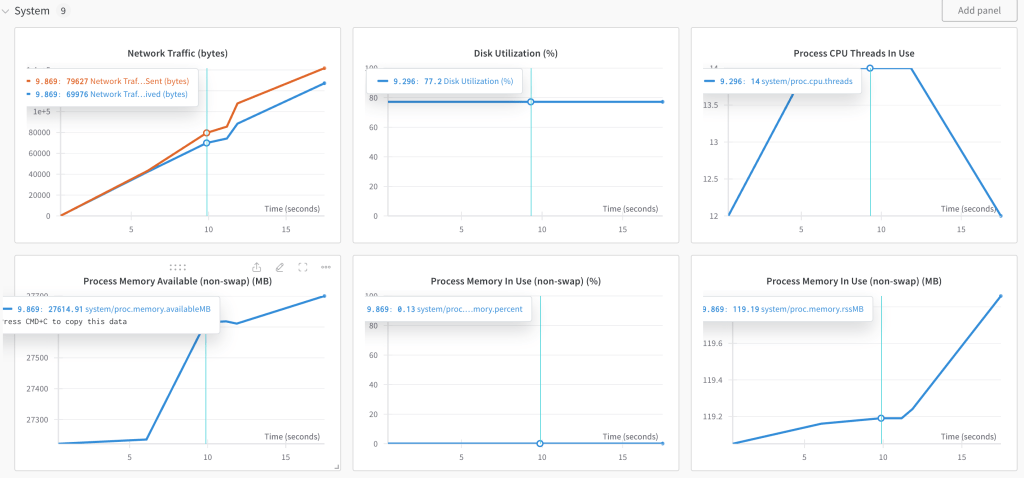
I can also compare memory performance of different model runs.
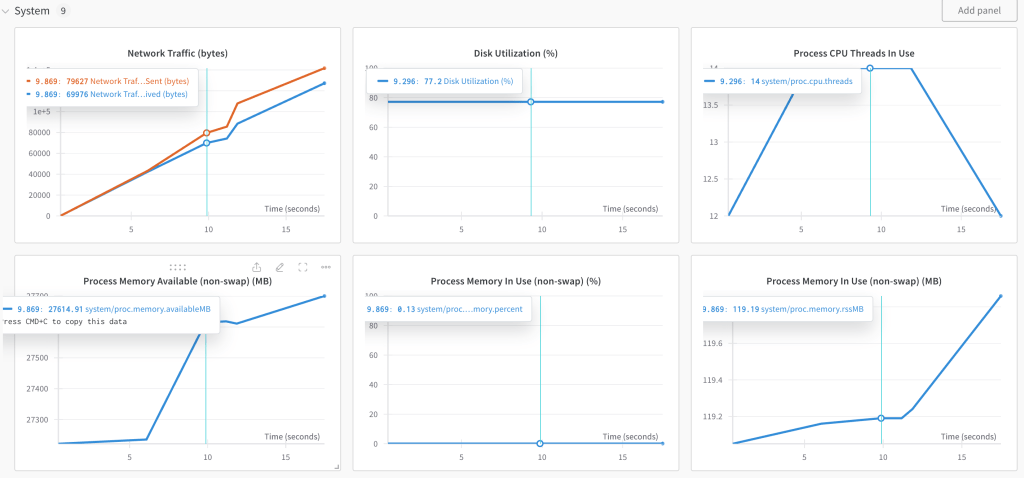
This helps with someone to visually compare LLM results along with the statistical measures computed.
This can further be exported as a CSV and results can be seen like below:-

This exercise I found is a very interesting piece. As to how do you formalise experiment tracking. This need not be a problem solved using a single tool but can be solved using any tool as we already have this information.
