In the world of LLM’s, rag has gained quite a bit of traction due to the fact that it helps reduce hallucination by giving access to LLM’s to external sources and grounding the results.
In simple words, RAG is basically proving an external data source for Generative AI models to get better context on user queries to providing better responses
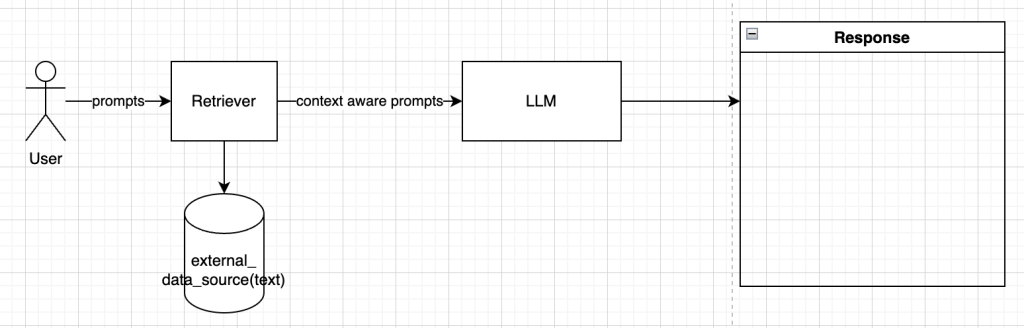
If you need to understand RAG, do checkout this article to get an overview of RAG(https://aiforproduction.wordpress.com/2024/01/24/understanding-rag-and-vector-db/).
SINGLE MODAL RAG:
Currently we are doing rag with single mode(text). The external data source currently contains only text(i.e text vector embeddings). This does solve a lot of problems with LLM’s.
The external data source is currently consisting of text, rather text embeddings.
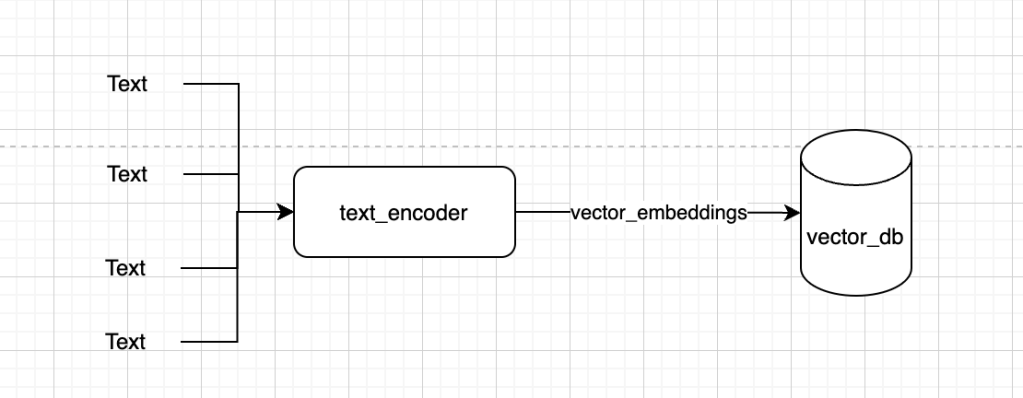
So when user gives a prompt, it searches the vector databases using cosine similarity or any other measure to get the most relevant information and uses this to provide better contextual information to LLM.
USE CASE TO SOLVE:
While this solves a lot of use cases. Data is generally of different kinds, text, images, video audio etc. Currently with the rag and LLM’s we have we are able to solve for use cases in text but we still lack in use cases that require different modes.
Eg. Read a 100 page financial report of a company which contains text, images and tables.
If we need to use LLM’s to retrieve and generate some information from it. Using traditional LLM’s we can’t solve this. There are few options in the market:
MULTI MODAL RAG(multi modal embeddings):
Your external data source is not a single type of data, but also comprises of images, video, audio etc. Since all of them will be stored as vectors in the vector db, a comparison between them is not as difficult.
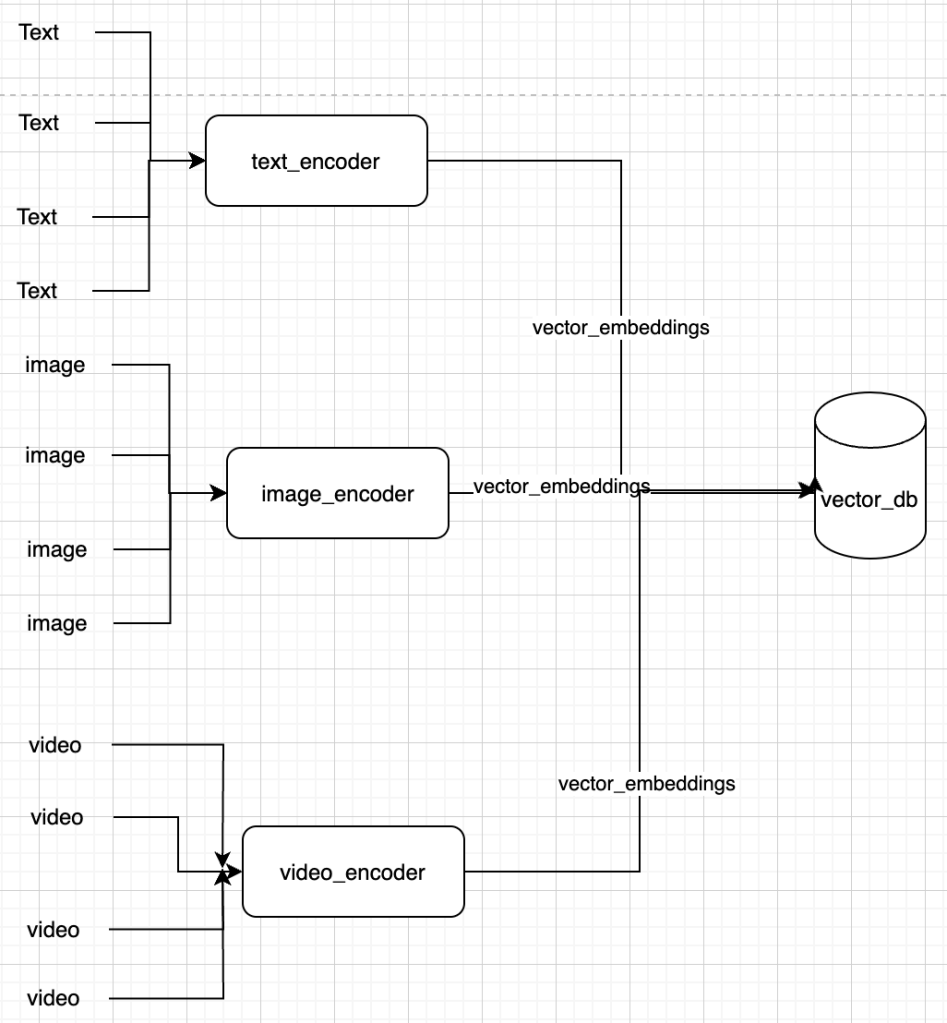
This looks like below:-

This opens up multiple possibilities for similarity search:
- Text to text
- Text to Image
- Image to Image
MULTIMODEL LLM’S
The easy part was the embeddings, now to actually achieve multi modality we need LLM’s that are trained on multi modal data. There are few options available:-
- Google Gemini(https://deepmind.google/technologies/gemini/#introduction)
- GPT4v(https://community.openai.com/t/gpt4-vgpt-4-with-vision-is-currently-available-to-all-developers/476745)
- open source models(https://huggingface.co/liuhaotian/llava-v1.6-mistral-7b)
- other open source models
I did try my hands with google gemini since they had more tutorials and sample code:-
WHAT COULD I SOLVE:
- Finding similar text based on user input prompt(using text embedding)
INPUT:

OUTPUT:

- Finding image based on user input prompt(using text to image embedding)
INPUT:

OUTPUT:
- Finding image based on user image prompt(using image embedding)
INPUT:

OUTPUT:
BUILD A MULTI MODEL RAG:
Now we can see that we can do search across multiple modes, next is implementing rag across multiple modes.

FINDINGS AND SUMMARY:
Multi modal RAG’s is a great step in solving different multi modal retrieval and generational problems and currently from what I research, I still see performance of open source LLM’s not to be in par with the proprietary LLM’s. And the below were issues with multi modal LLM’s:
- Data quality of text and images needs to be high
- As with all LLM’s the compute is higher and inference time is slower.
- Business will always want smaller models which cost lesser(so api vs quantized models)
- Might need more domain specific context in few industries
- Interpretability is low
So it is going to be an interesting space to watch out for understand. It would be interesting to see how this scales as the number of devices using LLM’s goes higher.
WHAT NEXT:
If one wants to experiment with multimodal rag and gemini, the below notebook is really helpful, fyi you need to have GCP credentials or cloud skill boost credits for the same.
