Context:
So for those who have just bumped into this article, to give a little context to what we did in a previous article(ML problems in production). We looked at how ML is in production, problems with ML in production, and the engineering components on machine learning. And finally how we can build our car- AI product.
So what we are doing in this article is look at the engineering components below and apply them to a real use case I had at work. Credit risk assessment.
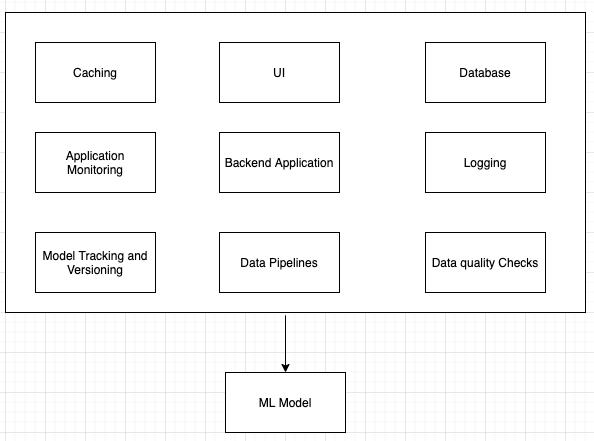
Use Case Analysis
So we saw the problem we had, we discussed a brief template of building a car, now let us look at an example of building one.
Credit Risk assessment Model :
Requirements:
We had a bank that wanted their asses the risk of their loan applications. They had past data about applicants and using that we wanted to check for risk. A classification problem.
Application details:
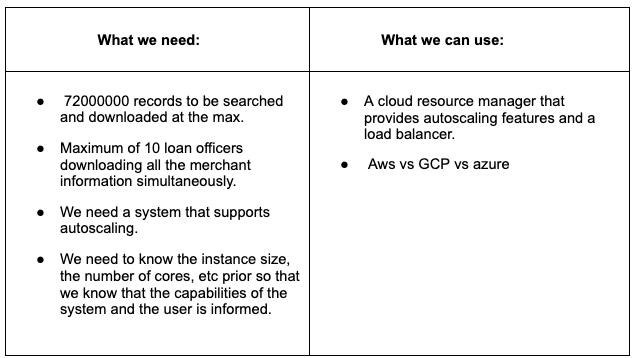
- An application where to search and export a single applicant or many(max of 100,000 applicants)
- Ability to upload merchant parameters each month they had computed at their end.
- UI to see the accuracy of the predictions.
What we started with:
- We had our data scientists build a credit scoring model.
- So the machine learning model is written in python. Not getting into the details of the model as here.
- Let’s consider that we already had a decent running engine 😛 But here is the catch.
- The different stages of ML. i.e preprocessing, training, scoring, postprocessing, etc. These were simple python scripts. We would pass a CSV path from the command line, finish one step and then run each ML step. Our input file is already generated by different systems. Take final output update the database.
What we needed:
A product that can be used by the user. Let us go back to the box now.

A Little thought on Each box now:
So now that we have our context, let’s think about building the car. We already have a working engine. ie. Credit risk assessment model.
Some questions that we ask when are designing the same:
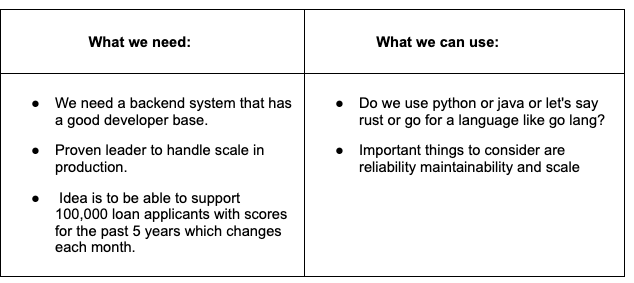
UI:

Backend:
Data Pipelines: This comes in 2 stages, 1.) Ingestion of data for ML models from different sources 2. )Automating the different stages of machine learning.

Data quality checks:
A very critical piece in the process is to actually monitor the data quality. We need this before your cleaning data and after the Ml stages are complete.

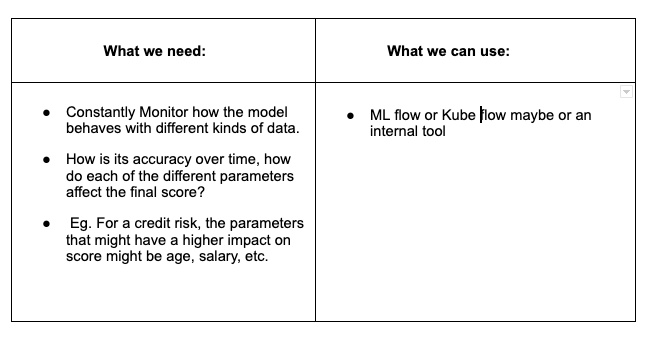
Model Tracking:
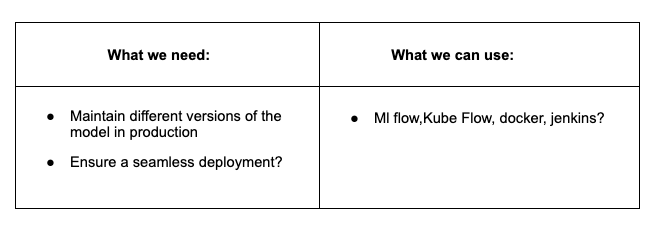
Model Versioning and Deployment:
Database:

External storage:

App Monitoring:

Logging:

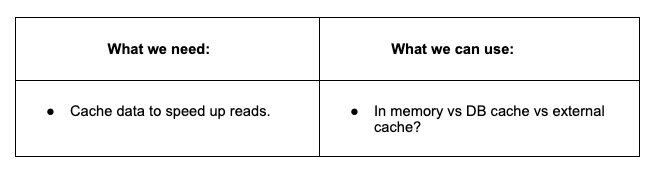
Caching:
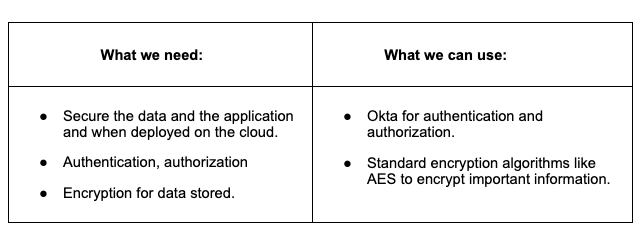
Data and Application Security:
Resource requirements:
Conclusion:
So this was just a small dive into the questions where we looked at, the thought process and so now let’s go back to this picture to end our conversation.
What I spoke of is a classification model and for a particular fintech use case. So the use case and the requirements will be different for each model and each industrial use case. Some like fintech need security, while some like e-commerce need scale. But still, the core concepts remain the same. And yes as you can see ML is much more than machine learning models. It is about data, it is about distributed systems and yes it is also about the engine. So yes I do look forward to building a lot more cars in the future. I wish to learn how to repair the engine if not build a new one
